Conceptos básicos de arquitectura de procesadores x86

Este post está creado para poder tener una base del funcionamiento de los procesadores de arquitectura x86, para poder llevar a cabo ataques de Buffer Overflow.
Conceptos básicos de la Organización del Sistema
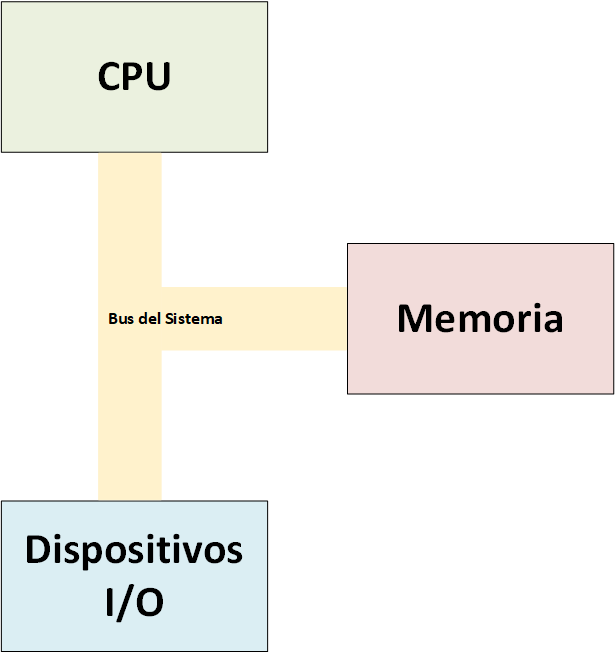
Dentro de la organización del sistema, podemos encontrar lo siguiente:
- CPU: Unidad de Proceso Central.
- Memoria: bloque de memoria donde los programas, datos, etc. son almacenados.
- Dispositivos I/O: dispositivos de entrada y salida, como monitores, tajera de red, entre otros.
Todos estos se encuentran conectados mediante un Bus del Sistema:
CPU (Central Process Unit)
La CPU es el dispositivo encargado de ejecutar el código máquina (o lenguaje máquina) de un programa, el cual, corresponde a un grupo de instrucciones.
Estas instrucciones son presentadas en binario al procesador (a nosotros se nos presentan en hexadecimal), pero como la mayoría no entiende esto, es necesario traducirlos en un lenguaje mnemotécnico, como es el caso del lenguaje Assembly (ASM).
Los assembler más populares son:
- NASM (Netwide Assembler).
- MASM (Microsoft Macro Assembler).
- GAS (GNU Assembler).
- FASM (Flat Assembler).
A continuación, se presenta un ejemplo de un programa, mostrando sus instrucciones en memoria tanto en lenguaje máquina (cuadro verde) como en assembly (cuadro azul):

Es necesario tener en cuenta que cada CPU tiene su propio set de instrucciones de arquitectura (ISA). Estos entregan todo lo necesario para quien quiera escribir un programa (memoria, registros, instrucciones, entre otros). Para nuestro caso, el ISA a revisar es el set de instrucciones x86, originario del Intel 8086.
[!info] El acronimo x86 hace referencia a la arquitectura de procesadores de 32 bits, mientras que x64 (también conocido como x68_64 o AMD64), hace referencia a la arquitectura de 64 bits. El número de bits equivale al ancho de los registros de la CPU.
Funcionamiento básico de la CPU
Cuando se habla de la CPU, es necesario tener en cuenta los siguientes componentes:
- Unidad de Control: recupera/decodifica instrucciones y recupera/almacena datos en la memoria.
- Unidad de Ejecución: la ejecución de instrucciones ocurre en esta sección.
- Registros: direcciones de memoria interna.
- Flags: Usados para indicar el estado de un programa cuando este se está ejecutando.

Registros GPR
Los registros GPR (General Purpose Registers) son porciones pequeñas de memoria que sirven como almacenamiento temporal de datos (similar a las variables).
Algunos tienen un propósito especial, mientras que otros son usados para almacenar datos.
Dentro de sus funciones están:
- Operandos para operaciones lógicas y aritméticas.
- Operandos para cálculos de dirección.
- Punteros de memoria.
La siguiente tabla presenta los 8 registros para la arquitectura x86:
| Nomenclatura | Nombre | Descripción |
|---|---|---|
| EAX | Extended Accumulator Register | Usado para operaciones aritméticas. Acumulador para operandos y datos de resultados. |
| EBX | Extended Base Register | Registro base para acceder a la memoria. Almacena la dirección base del programa. Puntero a datos en el segmento DS. |
| ECX | Extended Counter Register | Contador para operaciones de cadena y loop. |
| EDX | Extended Data Register | Utilizado en operaciones aritméticas y puntero de entrada/salida (I/O). |
| EBP | Extended Base Pointer | Conocido como puntero base o puntero de marco. Apunta al fondo del marco del stack actual. También puede ser utilizado para hacer referencia a variables locales. Puntero a los datos en la stack (en el segmento SS). |
| EDI | Extended Destination Index | Puntero a datos (o destino) en el segmento señalado por el registro ES. Puntero de destino para operaciones de cadena. |
| ESI | Extended Source Index | Puntero a los datos en el segmento señalado por el registro DS. Puntero de origen para operaciones de cadena. |
| ESP | Extended Stack Pointer | Apunta la parte superior del stack. Puntero de stack (en el segmento SS). |
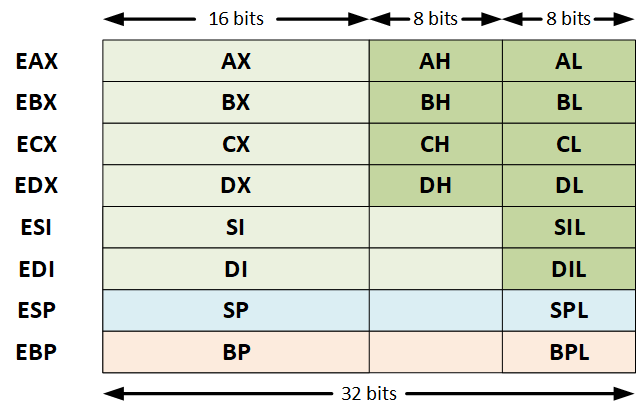
La tabla anterior muestra los registros para una arquitectura de 32 bits, pero estos pueden ser representados en las arquitecturas de 8 bits y 16 bits.
En 8 bits se define la memoria superior (los 8 bits superiores, representados por una H) y la memoria inferior (los 8 bits inferiores, representados por una L). En 16 bits, estos dos se unen y se utiliza una X. Cuando vemos los registros de 32 bits, a estos se le agrega una E, y en 64 bits esta es reemplazada por una R:
Registros de Segmentos
Son registros de 16 bits que identifican un segmento en la memoria. Para acceder a un segmento particular en la memoria, el registro de segmento para esa unidad debe estar presente en el registro apropiado.
El uso de estos dependen del tipo de modelo de administración de la memoria del sistema operativo o el que lo ejecuta.
Cada registro de segmento está asociado a uno de los siguientes tipos de almacenamiento: código, datos, stack.
- Registro CS: contiene la dirección de segmento para el segmento de código, donde, se almacenan las instrucciones que se ejecutan.
- Registro DS: permite un acceso eficiente y seguro a diferentes tipos de estructuras de datos.
- Registro SS: contiene la dirección del segmento SS, donde el stack de procedimientos se almacena para el programa, tarea o controlador que se está ejecutando actualmente. Todas las operaciones del stack utilizan el registro SS para encontrar el segmento del stack.
- Registro ES: registro adicional para almacenar datos.
- Registro FS: registro adicional para almacenar datos.
- Registro GS: registro adicional para almacenar datos.
Registros de estados EFlags
Estos registros de 32 bits almacenan varios indicadores de estado, uno de control y un grupo del sistema.

Cabe destacar, que para procesadores de 16 bits, estos se llaman Flags, para 32 bits EFlags, y para 64 bits RFlags.
Los Flags de estado indican los resultados de las instrucciones aritméticas:
- CF: bit 0, este flag indica una condición de overflow para la aritmética de enteros sin signo. También se usa en aritmética de precisión múltiple.
- PF: bit 2, se establece si el byte menos significativo del resultado contiene un número par de 1 bits.
- AF: bit 4, se establece si una operación aritmética genera un acarreo o un préstamo del bit 3 del resultado. Este indicador se utiliza en aritmética decimal codificada en binario (BCD).
- ZF: bit 6, se establece si el resultado es cero.
- SF: bit 7, se establece igual al bit más significativo del resultado, que es el bit de signo de un entero con signo. (0 indica un valor positivo y 1 indica un valor negativo).
- OF: bit 11, se establece si el resultado entero es un número positivo demasiado grande o un número negativo demasiado pequeño (excluyendo el bit de signo) para caber en el operando de destino. Este indicador especifica una condición de overflow para la aritmética de entero con signo.
El flag de control (DF - Direction flag, bit 10) controla las instrucciones en cadena. Si este se encuentra activado, las instrucciones en cadena disminuyen automáticamente.
Y por último, se tienen los flags de sistema y el campo IOPL. Estos registran el control del sistema operativo o las operaciones ejecutadas (estos no deben ser modificados por las aplicaciones):
- TF: bit 8, configurado para habilitar el modo de un solo paso para el debugging.
- IF: bit 9, configurado para responder a interrupciones enmascaradas.
- IOPL: bit 12 y 13, indica el nivel de privilegio de entrada/salida del programa o tarea actualmente en ejecución.
- NT: bit 14, controla el encadenamiento de tareas interrumpidas y llamadas. Se establece cuando la tarea actual está vinculada a la tarea ejecutada previamente.
- RF: bit 16, controla la respuesta del procesador a las excepciones de debug.
- VM: bit 17, se establece para habilitar el modo virtual-8086.
- AC: bit 18, si el bit AM se establece en el registro CR0, la comprobación de alineación de los accesos de datos en modo de usuario se habilita si y sólo si este flag es 1. Si se establece el bit SMAP en el registro CR4, se permite el acceso explícito de datos en modo supervisor a las páginas en modo usuario si y sólo si este bit es 1.
- VIF: bit 19, imagen virtual del flag IF. Se usa junto con el flag VIP.
- VIP: bit 20, se establece para indicar que hay una interrupción pendiente. Se usa junto con el flag VIF.
- ID: bit 21, la capacidad de un programa para establecer o borrar este flag indica la compatibilidad con la instrucción CPUID.
Registro EIP
El registro EIP (puntero de instrucción) contiene el desplazamiento (offset) en el segmento de código actual para que se ejecute la siguiente instrucción. Se avanza del límite de instrucciones al siguiente segmento del código en línea recta o se mueve hacia adelante o hacia atrás mediante una serie de instrucciones ( JMP, Jcc, CALL, RET e IRET).
El software no puede acceder directamente al registro EIP, este se controla implícitamente mediante instrucciones de transferencia de control (como JMP, Jcc, CALL y RET), interrupciones y excepciones.
La única forma de leer el registro EIP es ejecutar una instrucción CALL y luego leer el valor del puntero de instrucción de retorno del stack. El registro EIP se puede cargar indirectamente modificando el valor de un puntero de instrucción de retorno en el stack y ejecutando una instrucción de retorno (RET o IRET).
Proceso de la memoria
La memoria del procesador se encuentra dividida en 4 regiones:
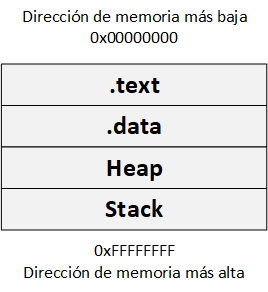
- Text: también es conocida como instrucción de segmento. Es definido por el programa, y contiene el código de este (instrucciones). Esta región es marcada como read-only.
- Data: esta región se encuentra dividida en dos: datos inicializados y datos no inicializados.
- Datos inicializados: incluye items como variables globales y estáticas declaradas que fueron predefinidas y pueden ser modificadas.
- Datos no inicializados: también conocido como BSS (Block Started by Symbol); además, comienza las variables que se inicializan a cero o que no tienen una inicialización explícita (por ejemplo, static int t).
- Heap: este inicia después del segmento BSS. Esta porción de memoria es usada cuando se necesita más espacio por parte del programa, como por ejemplo, llamadas de sistema brk y sbrk, usados por malloc, realloc y free. Se asigna/revoca de forma manual.
- Stack: es el bloque de memoria LIFO (Last-in First-out). Se encuentra en la parte alta de la memoria, y es donde se almacenan las variables cuando se encuentra en ejecución una función de un programa.
Stack
Es una matriz contigua de ubicaciones de memoria. Está contenido en un segmento e identificado por el selector de segmento en el registro SS.
La siguiente imagen, muestra una representación del stack:
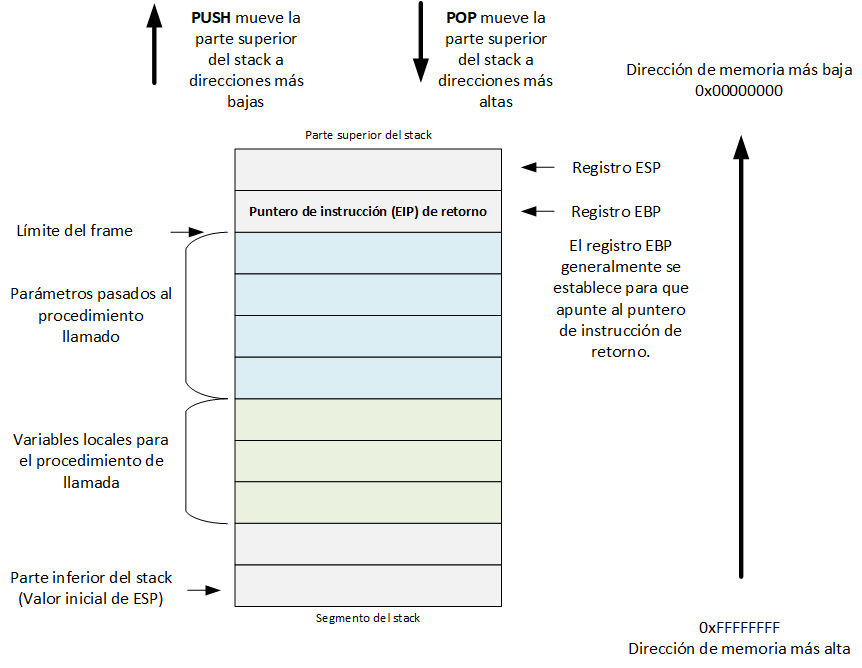
Es necesario tener en cuenta que dentro de las principales diferencias que posee el stack con el heap, es que el stack crece hacia la dirección de memoria más baja, mientras que heap lo hace hacia la dirección de memoria más alta:
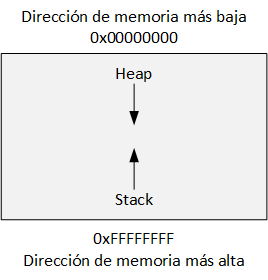
Como se comentó antes, el stack es una estructura LIFO, donde las operaciones fundamentales son PUSH y POP.
- PUSH: agrega elementos a la parte superior del stack. En una arquitectura de 32 bits va disminuyendo de 4 bytes, mientras agrega elementos al stack (en 64 bits, la dirección de la memoria va disminuyendo en 8 bytes).
- POP: retira el último elementos del stack. Realiza lo contrario a PUSH, en vez de disminuir la dirección del stack, lo va aumentando.
[!info] Cada vez que se usa PUSH y POP, el registro ESP es modificado, apuntando a la parte superior del stack.
Stack Frames
Los stack frames son porciones o áreas del stack que son agregadas (usando un PUSH), cuando llaman una función, o retiradas (con un POP) cuando se retorna un valor.
Por lo tanto, cuando una subrutina o un procedimiento es iniciado, un stack frame es creado asignándole el ESP (puntero stack) actual. Cuando la subrutina/procedimiento finaliza, el EIP (puntero de instrucción) es restablecido a la dirección de la llamada inicial.
A continuación, dejo un ejemplo de stack frame del siguiente código:
int a() {
return 0;
}
int main() {
a();
return 0;
}
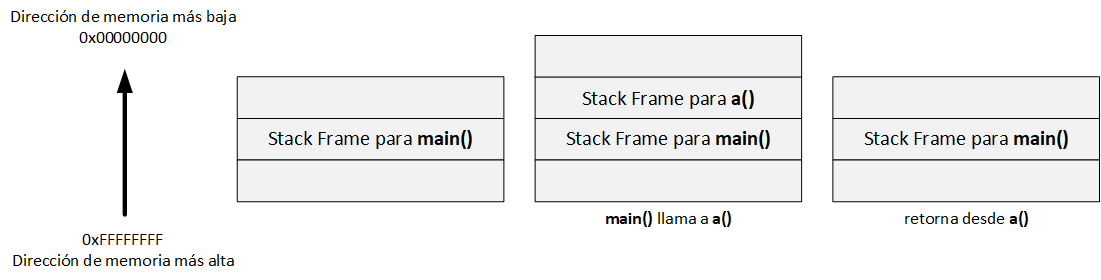
Prólogo y Epílogo
Las funciones que podemos encontrar cuando se agregan o retiran elementos del stack son:
- Prólogo: prepara el stack para ser usado. Este ocurre para cada función, y cuando la función que es llamada toma el control, ejecuta las siguientes instrucciones:
push ebp ; guarda el valor del antiguo EBP en el stack
mov ebp, esp ; copia el valor de ESP en el puntero EBP, creando un nuevo stack frame
sub esp, X ; resta X del stack pointer (ESP), haciendo espacio para variables locales
- Epílogo: retorna el control al que realiza la llamada de la función anterior. Reemplaza el ESP con el EBP actual. Restaura su valor antes del prólogo mediante un POP del EBP desde el stack. Regresa al que llama haciendo un POP del EIP (almacenada en el stack) y luego salta a ella.
Ejemplos de epílogo:
leave
ret
o:
mov esp, ebp
pop ebp
ret
Ejemplo del stack frame con prólogo y epílogo:
void function1(int l, int m) {
int x = 21;
int y = 22;
}
int main(int argc, char *argv[]) {
int a = 1;
int b = 2;
funtion1(11, 12);
return 0;
}
Paso 1:
Lo primero que sucede en al iniciar este programa, es que los parámetros de la función main (argc y argv) son agregados al stack (de izquierda a derecha):
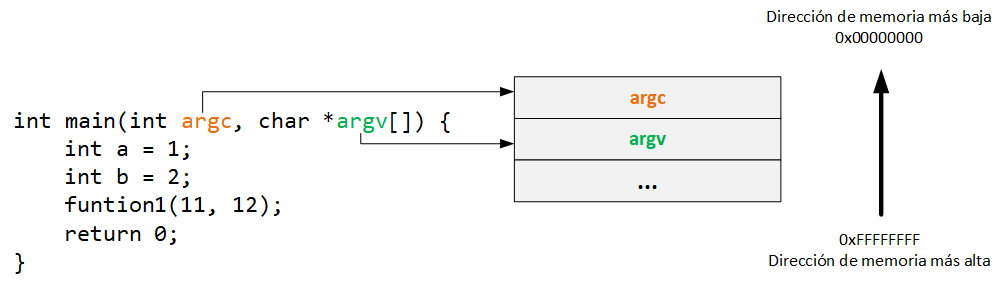
Paso 2:
Luego se llama la función main y la CPU realiza un PUSH del contenido del EIP en el stack, y señala el primer byte después de la instrucción CALL (se necesita saber la dirección de la próxima instrucción para poder proceder cuando regresemos de la función llamada).
Paso 3:
El que llama (en este caso el sistema operativo) pierde el control, y el que es llamado (función main) toma el control:
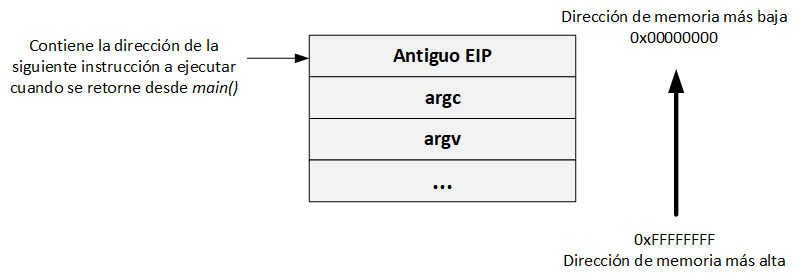
Paso 4:
Como estamos en la función main, se crea un nuevo stack frame, el cual, es definido por el EBP y el ESP; almacenando el EBP actual en el stack, con el fin de poder saber que estamos volviendo a la función que llamó a main. Cuando el valor del EBP es almacenado, este es actualizado, y ahora apunta a la parte superior del stack:
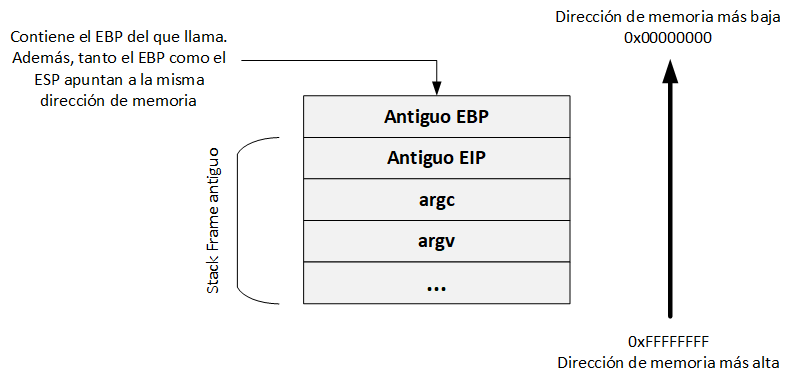
Este paso corresponde al prólogo, el cual, crea espacio suficiente en el stack, donde, se pueden copiar las variables locales:
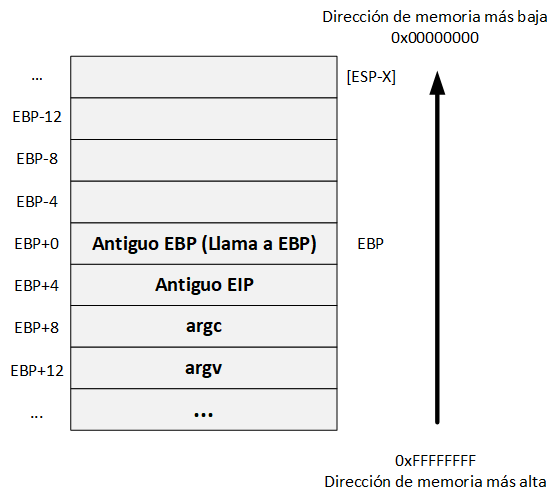
Paso 5:
Cuando el prólogo termina, se completa el stack frame de main, y las variables locales son copiadas en el stack.
Ahora se tiene que definir el valor del ESP, el cual, indica la parte superior del stack. Esto se logra con la siguiente instrucción:
mov DWORD PTR [esp+Y],0x1
La instrucción anterior mueve el valor 0x1 (el valor de la variable de a) a la ubicación de la dirección de memoria apuntada a ESP+Y. ESP+Y apunta a una dirección de memoria entre EBP y ESP.
Es necesario tener en cuenta que esto se realiza para cada variable:
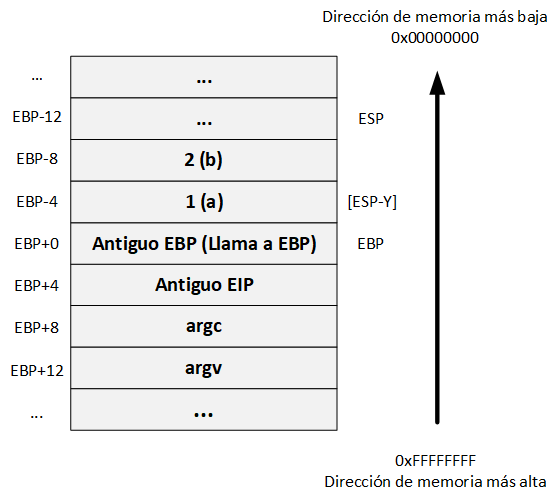
Paso 6:
En este punto, main comienza con el llamado a la función function1, realizando lo siguiente:
- Realiza un PUSH de los parámetros de la función en el stack.
- Llama a function1.
- Ejecuta el prólogo (lo que actualizará el EBP y ESP para crear un nuevo stack frame).
- Asignará las variables locales en el stack.
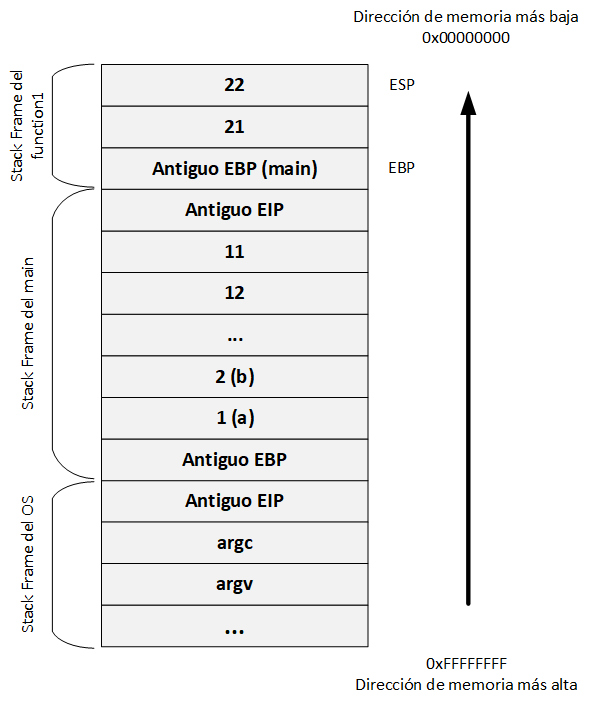
Paso 7:
Ahora que la función function1 se ha ejecutado por completo, se realiza un retorno al stack frame anterior mediante el epílogo.
[!info] Cabe destacar, que aunque no tenga un
returnen el código, cuando el programa deja una subrutina, seguirá ejecutando el epílogo.
Lo primero que hace el epílogo es mover EBP en ESP (mov esp, ebp), dejando a los dos apuntando a la misma dirección.
Luego realiza un POP del EBP (pop ebp), dejando el valor de EBP en la parte superior del stack. Dado que la parte superior del stack apunta a la ubicación de la dirección de memoria donde se almacena el antiguo EBP (el EBP que llama), se restaura el stack frame del que hace la llamada.
[!note] Recordar que la instrucción POP actualiza el valor del ESP. Ahora el ESP apunta al EIP almacenado anteriormente.
Y la última instrucción que ejecuta el epílogo es el RET.
La instrucción RET muestra el valor contenido en la parte superior del stack en el EIP anterior, y salta a dicha dirección de memoria devolviendo el control del que llama a la función.
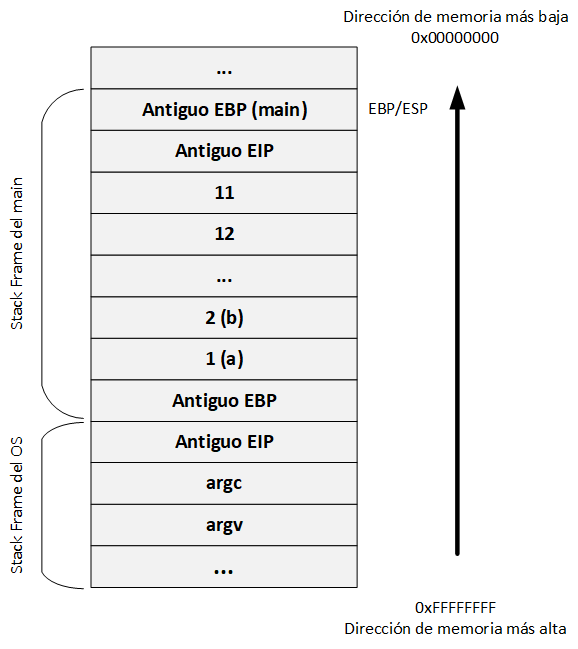
Esto se repite hasta que finaliza la ejecución del programa.
Endianness
Los endianness son una representación o almacenamiento de valores en memoria.
Existen 3 tipos de endianness, los cuales son:
- Big-Endian
- Little-Endian
- Mixed-Endian
En este post solo se explicaran big-endian y little-endian, debido que mixed-endian rara vez es utilizado.
El saber sobre endianness ayudará al momento de escribir un payload para explotar un Buffer Overflow.
La representación de big-endian el LSB es almacenado en la dirección de memoria mayor. Mientras que, el MSB es almacenado en la dirección de memoria más baja.
En el siguiente ejemplo se tiene el valor hexadecimal 0x12345678, teniendo en cuenta que +0 apunta a la dirección más alta y +3 apunta a la dirección más baja:
| Dirección en memoria | Valor del byte |
|---|---|
| +0 | 0x12 |
| +1 | 0x34 |
| +2 | 0x56 |
| +3 | 0x78 |
En little-endian es lo contrario, el LSB es almacenado en la dirección de memoria más baja, mientras que, el MSB es almacenado en la dirección de memoria más alta.
En el siguiente ejemplo se tiene el valor hexadecimal 0x12345678, teniendo en cuenta que +0 apunta a la dirección más alta y +3 apunta a la dirección más baja:
| Dirección en memoria | Valor del byte |
|---|---|
| +0 | 0x78 |
| +1 | 0x56 |
| +2 | 0x34 |
| +3 | 0x12 |
Por lo tanto, si ahora tenemos el valor 11 decimal (en hexadecimal es 0B), la notación en little-endian sería:
| Dirección en memoria | Valor del byte |
|---|---|
| +0 | 0x0B |
| +1 | 0x00 |
| +2 | 0x00 |
| +3 | 0x00 |
Esto si lo vemos en un debugger, se representaría de la siguiente forma:
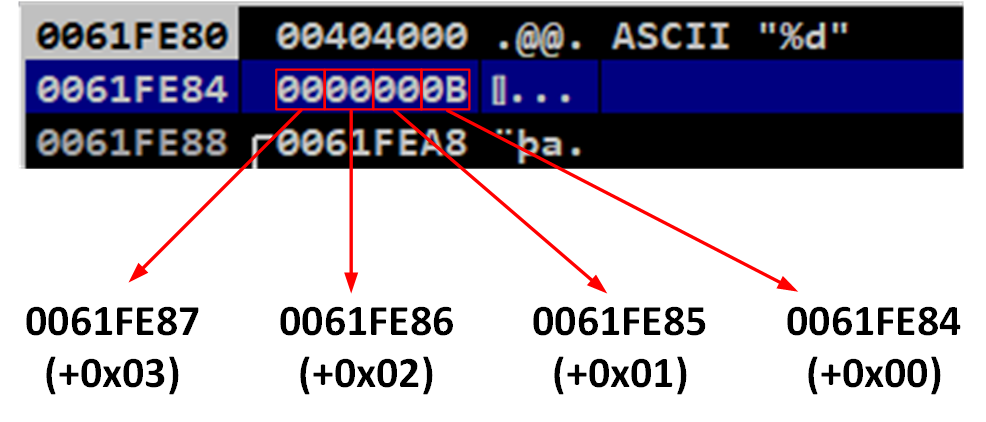
MSB
En binario, el bit más significativo es el valor más grande, leído de izquierda a derecha. Por lo tanto, si tenemos el binario 100, el MSB es 1.
LSB
En binario, el bit menos significativo es el valor más bajo, leído de derecha a izquierda. Por lo tanto, si tenemos el binario 110, el LSB es 0.
NOPs
Dentro de los tópicos importantes y que se deben saber como base al momento de realizar un Buffer Overflow son las instrucciones NOP (No Operation).
Este corresponde a una instrucción en assembly que indica hacer nada. Esto significa que cuando el programa encuentra un NOP al momento de su ejecución, este simplemente lo omite y saltará a la siguiente instrucción.
En arquitectura de procesadores x86, estas instrucciones son representadas por el valor hexadecimal 0x90.
La razón de ver los NOPs es que, al momento de realizar un ataque de Buffer Overflow, este debe coincidir con el tamaño y la ubicación específica que el programa espera.
Para lograr esto, es que se utiliza la técnica NOP-sled, el cual, nos permite llenar una porción del stack con NOP, permitiéndonos llegar a la instrucción que deseamos ejecutar.
Protecciones
A lo largo de los años, se han desarrollado múltiples implementaciones de seguridad para prevenir la explotación de vulnerabilidades de Buffer Overflow:
- ASLR (Address Space Layout Randomization)
- DEP (Data Execution Prevention)
- Canary (Stack Cookies)
ASLR
Esta protección introduce la aleatoriedad para los ejecutables, bibliotecas y stacks en el espacio de direcciones de la memoria, esto significa que, cuando se ejecuta múltiples veces el mismo programa, cada vez es ubicado en diferentes direcciones de memoria.
El problema de ASLR es que no se habilita para todos los módulos, por lo tanto, cuando un proceso tiene ASLR habilitado, puede que un DLL en el espacio de direcciones no tenga esta protección, y así podría realizarse un bypass de este.
Para poder validar si un programa utiliza ASLR (u otra protección), se puede utilizar el programa de Microsoft Process Explorer.
Para poder ver esta columna, debemos hacer clic derecho en el nombre de una de las columnas y hacer clic en Select Columns…:
Luego seleccionamos la columna que deseamos ver, que en este caso es ASLR Enabled:
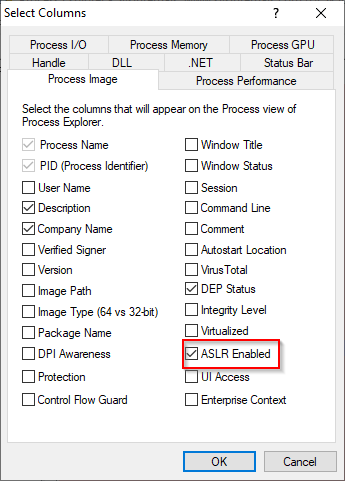
Y con esto podemos ver si este se encuentra habilitado o no:

Además de esto, Microsoft posee la herramienta EMET (Enhanced Mitigation Experience Toolkit), que ayuda a solventar problemas de explotación, brindando a los usuarios la habilidad de desarrollar tecnología de mitigación de seguridad en todas las aplicaciones.
DEP
Es una medida defensiva para hardware y software que previene la ejecución de código de zonas en la memoria que no están explícitamente marcadas como ejecutables.
Canary
También conocida como Stack Cookie. Es una implementación de seguridad que coloca un valor al lado de la dirección de retorno en el stack.
El prólogo de la función carga un valor en esta ubicación, mientras que el epílogo se asegura de que el valor esté intacto. Como resultado, cuando se ejecuta el epílogo, comprueba que el valor todavía está allí y que es correcto.